In his CM: the Next Generation series, Joe Farah gives us a glimpse into the trends that CM experts will need to tackle and master based upon industry trends and future technology challenges.
If you're planning a configuration management (CM) project, it's time to put together a CM Plan. A CM plan can take on many forms and the CM Crossroads site is a great place to investigate what goes into a plan. In this article I'm going to concentrate on a number of areas that need to be addressed in your plan in order to follow best practices.
What's Your Product Road Map
You may be putting together a CM plan for a project, or for an entire organization. One of the first things that you need to do is to consider which products (including process products) are going to be managed under your CM plan. You then need to look at the products and for each identify the product road map. If you're creating software for a one-time event, such as the display controller for the celebration of a new millennium, you may only have one release of the software to worry about. Your product road map will be a straight line targeted towards the millennium celebration.
But most software will have an ongoing sequence of major releases, with perhaps some milestone releases in-between. A product road map for something like Microsoft's Windows OS might look something like the one below, with the dotted line representing today:
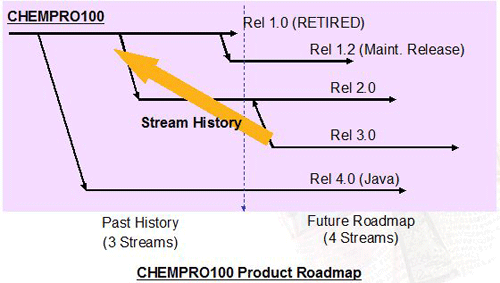
This roadmap, which will grow over time, gives an important framework to the product team. This is an important step.
You'll want to identify the expected release lifetime, from a support perspective. You'll likely want to address your methodology (Agile with iterative customer involvement vs. releases with feedback loops for acceptance and for next release requests). How often are you going to have releases? All of these questions should be answered to help frame the context of your CM plan. They should also be examined across all products to which your CM Plan is going to apply. In other words, your CM plan has to set the parameters for its valid use.
Requirements Management
Requirements are an integral part of CM. For software, proof of satisfying the requirements forms the basis of your functional configuration audit (FCA). So just as important is your test suite management, but will address that later.
If you're starting a project, or even continuing one that wasn't managed well, make sure you know where your requirements are coming from. If you have an agile process, your requirements may start off as customer requirements and be converted into product requirements over a series of iterations with feedback. Perhaps your design team has all the expertise necessary to get the first release out, or perhaps your requirements are dependent primarily upon the competition (e.g., it has to do X, Y, Z and do everything the current market leader does). Some of your requirements may come from industry standards. You need to identify your valid sources of input and have a mechanism in place to capture such input.
Your requirements should form a hierarchy for each product. Products may share portions of the hierarchy, you have to have a root point under which you can collect requirements so that you may identify what your entire set of requirements are and ensure reasonable completeness. Identifying the correct set of requirements is perhaps a bit off topic here, but, you do need to manage this set so that you can assess it for completeness, correctness, etc. How detailed each requirement is may be a project decision, but your CM plan must specify sufficient detail of management so that a requirements traceability matrix and an FCA are both within your grasp.
Equally important to collecting your requirements is requirements change management. How and when are requirements allowed to change? Does the development team work to a requirements baseline until the release is out the door and then work on changes, or are your requirements incrementally modified throughout the design and implementation cycles? There are differing opinions on what the best practice is here, but your CM Plan should allow the flexibility required for your product road map(s). What tools and methods are you using to track change requests and changes to the requirement baseline? What level of traceability is required (do the tools support this?) do your processes support this? Who approves changes (e.g., the customer or the market representative) and what is the formal procedure for establishing a contract with the development team?
Requirements Allocation and Project Management
The next area of your CM Plan has to deal with how requirements and requirement changes get mapped onto development team tasks. Presumably the development team is working towards the next release. Some requirements are targeted for that release, while others are targeted for later releases. The requirements management tools should be able to help you to sort this out.
Whether you allocate customer requirements to product requirements to design requirements, or create functional specification tasks which map back to the customer requirements and which specify the Product functionality, and then design tasks which map back to the functional specifications, is mostly just a matter of terminology (important terminology though). The key difference in these approaches is usually centered around the tools. One tool set may deal with requirements, and not with tasks, while another may deal with both requirements and tasks. In the former case, a separate project management tool is necessary to manage your tasks. In the latter case, it's integrated. I prefer the latter because customer requirements are not fully under the product team's control. Product and design requirements are, subject to satisfying the customer requirements. As such, you need different tools: customer requirement management, vs. product development tools. The allocated requirements map directly to tasks that have to be tracked, scheduled, prioritized, etc.
Regardless, features will get assigned to development managers who in turn identify the tasks required to complete the feature. Development managers also need to prioritize and assign these tasks to minimize impact on resources while also minimizing the risk to schedule and to quality. You have to make sure, through all of this, that traceability is maintained.
How Do These Tasks Map to Source Changes?
A task may be easy for one developer to complete in a short time frame, or may require extensive work over a longer period of time. The developer should be able to take the feature tasks and map them onto one or more change packages, or updates as we'll refer to them, which will be used to complete the task. Sometimes more than one update is required to ensure a smooth upgrade path. Sometimes the more risky parts are required earlier in the process to allow time to absorb the risk. Sometimes part of the task has to be completed by a different developer. In these scenarios, multiple updates may be required to complete a task. All should be traceable to the task and should specify any dependencies upon related updates. Does the developer have the flexibility to decide upon update packaging, or is this a directive from the line manager? Your CM plan needs to clearly specify these capabilities or you may risk ending up with processes and or tools that are inadequate.
Working with Change Packages/Updates
Your tools need to support change-based operations for your software updates. If your tools only support file-based operations, your developers will be checking in files one at a time, associating each file with the task, building delta reports by piecing together multiple file deltas, doing promotion file by file, and so forth. Change-based operations need to be central to your CM Plans. If your tools don't measure up, change them so that they do. File-based operations might cut it for small programs involving very infrequent changes, but even there the manual effort is going to lead to quality problems. Check-in should be a single change-based operation, as should promotion, delta reporting and traceability linkage. Get your developers out of the mode of looking at files and revisions, and into the mode of looking at changes.
This is an essential directive of a CM Plan. It is not optional. File-based CM will give you quality problems and overhead that you will not be able to handle in any reasonably large project. In effect, you will end up adjusting your tools to compensate for the fact that you don't have real change-based CM.
How Does Your File Branching Map to Your Product Road Map
Your CM Plan has to address your branching structure. This is a difficult issue. Many CM managers are familiar with the way CM worked in their earlier projects, and the efforts taken to ensure that it would work, because of its fragile nature. Most CM managers will not look into why CM is fragile, though. Branching architecture has a lot to do with it. A predictive branching architecture is one where tools can both help you with the branching requirements, and easily, and automatically, navigate branching history as necessary. An ad hoc architecture may seem to work, but you're not going to get a lot of help from your tools other than providing you with a labeling mechanism, which if used improperly, could bring the project to a halt. So let's look at branching in more detail so that your CM plan can give some good direction.
In software, it's easy to make a copy of something and change it. When two or three developers do this in parallel, it is known as a parallel change. When a project needs to develop release 2 of a product while supporting release 1, this is known as parallel development. For new releases, parallel development means creating parallel copies, known as parallel Branches, of software files when implementing new features. Fixing problems may or may not result in parallel copies. If you want the fix in both releases and the files being changed have not yet changed since release 1, you can fix it in release 1 and get the fix for free in release 2, at least if your tools and processes allow this. Some tools will have you clone your entire product for a new release, forcing you to make the same fix in two (or even multiple) places.
Parallel development is a valid reason for creating a new branch of a file. Parallel changes generally are not a good reason (with exceptions). The reason many tools and processes suggest parallel branches for parallel changes is that they don't have a mechanism to track the fact that changes are going on in parallel. The update mechanism should support this without the need for creating and tracking parallel branches.
Branching is often used for keeping track of feature development, for grouping file revisions based on promotion level (i.e., highest test status attained), and for numerous other reasons. Branching is a powerful concept. In fact, that is precisely why the use of branching is overloaded. When tools have insufficient means for managing the promotion levels, parallel changes, or any number of other requirements of SCM, the process turns towards the use of branching, merging and labeling to fill in. The result is an unsightly maze of spaghetti branches. Multiply this times thousands of files and you have a technology transfer nightmare ready to happen - along with a need for complex branching strategies
When using the right tools and processes, branching should primarily follow your product road map - one main branch per release. When a file is first changed in that release, create that release branch for the file - a good tool will even automate this for you. Resist creating branches for any other reason - which is not so easy if you have the wrong tools or processes. Then your branching is well organized. Your branch history is clear, as each file follows (possibly a subset of) the branch history for the product. Automation becomes simpler because your tools and processes can anticipate the need for branching. They can identify common ancestors for merging or the revisions to be used when a file branch doesn't exist for a particular release.
To some this sounds like an incredibly simplistic model and it is. That's why it's only possible if you have the right support mechanisms and algorithms to support it. I've used this model for over a quarter of a century and would never consider abandoning it. Perhaps there are some subtle variants I would consider, but having the tools manage the parallel development, build and baseline definitions, parallel checkout and promotion levels is just so much better than having to create and implement branching, labeling and merging strategies to do the same.
Build Automation and Tracking
"Build" is a term used for the process of taking source code and converting it into a set of deliverables (i.e., executables and other run-time files). In today's development arena, builds are done by programmers, by system integrators, by verification and production teams. A record of what was built (and how), is known as a build record, or often just a build (i.e., the object rather than the process).
Obviously, automating builds can save a lot of people a lot of time, but the real driver for build automation is to improve and ensure quality of your deliverables. Builds that are done manually are always subject to human error and I've seen countless examples of hours, or even days, being spent unraveling such errors. The time lost is one thing, but if you cannot guarantee that what went into the build is what you wanted to go into the build, then your customers will eventually call you to let you know. Your CM plan has to specify that builds will be automated.
Automating a build process requires the right tools. The build process involves a few steps:
(1) Identifying what you want in the build
(2) Retrieving the source code that reflects what you want
(3) Running a build operation (series of complies, links, etc.)
(4) Packaging up the results into a deliverable format
Ideally, the identification step is done through some gating procedure which allows only approved changes through. Sometimes the gating criteria might be "everything that the developer has said is ready". Other times it might be "only those changes which fix critical release problems". With some tools you may automate both of these types of selection processes (as well as others), while some require a manual selection process, typically because of a lack of traceability capability.
In any event, a key to successful automation here is to have other best practices in place that ensure peer reviews of each update and unit testing of each update (by the developer) is done before the developer signals that the update is ready. Your CM plan must mandate these (and/or other) quality assurance practices before code reaches the build team.
Given that you have identified what will go into the build, any half-decent CM tool should allow you to retrieve exactly that source code in a simple operation. If it doesn't, you're going to have quality problems. One note here is that, except for builds done in a developer's own workspace, never copy files into the build directory (or tree). Always retrieve them using an automated process from the repository. It doesn't matter if you retrieve all of them or just an incremental set, as long as the process for doing so is automated. If the process has errors, correct the process, not the result.
Generally make file,s or similar build directions, are used both to run the build operation and to package up the deliverables. These are process description files that say how to operate on the files retrieved for the build operation. In some cases, these files can be automatically generated from the CM and/or IDE tools . This is a great feature, as they are typically complex in format and semantics.
Variant Handling
So many projects start out as a one of, and then split off into dozens, if not hundreds, of variants of a product. Managing large numbers of baselines, builds, etc. is not only tedious and resource intensive, but it's risky. Sooner or later you're going to reach a point where you cannot cope. I've seen it more than often enough.
Your CM Plan has to specify design criteria which will make CM manageable. CM does not solve software engineering problems, but rather it helps you to identify them. Variant handling is one area where software engineering needs to take the lead.
It is not at all difficult to avoid dozens of variants. In fact, it's actually easier than not doing so. But it needs some simple rules up front. A variant will not be a build time variant, or a load time variant, if it can be a run-time variant. You need big, medium and small sizes. You can create separate images that support each of these, but you can just as easily add a requirement to the design team that says, the size will be configured at run time by setting a size parameter. Similarly, this applies to language, optional components, etc. There will be a run-time parameter governing each of these.
Your CM plan must explicitly state this because it's not going to get stated otherwise. Presto! All software design steps have this as a requirement. Instead of allocating a fixed number of resources, they make the allocation parameter a variable that can be adjusted prior to the resources being allocated. That was easy. It may help to have someone work on a user interface or database table that tracks and manages system parameters. Other than that, most variant problems are solved. There's still one, for the moment (but not too much longer) that's hard to get around: different builds for different platforms. One day this will disappear into a run-time switch as well (and Java is just one approach to this).
Testing Overview
Your CM Plan should specify a number of levels of testing. Some might have more levels than others, perhaps involving air worthiness and/or standards compliance. Others might simply need testing to the product requirements. There are a number of testing areas to consider. Your Plan must identify guidelines. Specify the testing areas and define their goals. Make sure that when the test architecture is laid out, that these goals are met. Adjust the levels/areas of testing as necessary to accomplish the goals you need. Spell out the goals in terms of the products you are producing. Some of the testing areas will be quite common while some may be very specific to your vertical or even to your application or system.
Unit testing: In software, unit testing usually refers to one of two things. First, verification of the functionality of an API (traditional meaning) or, second, verification of the functionality of a change. The latter is the more frequent type of testing that a developer needs to be doing. Before check-in unit testing should be documented and completed successfully by the developer.
Sanity testing: When multiple changes are being integrated by multiple developers, ensuring that the resulting product has sanity is essential. One change can break the build. Frequent sanity testing makes it easier to find out what change broke the build. Some applications can avail themselves to continuous integration and sanity testing. Others require regular builds and sanity testing. The goal here is to ensure that the development test bed remains sane and that the product quality is not heavily impacted by the recent set of changes.
Integration testing: When the changes come together, the functionality that was provided by each of the changes needs to be tested out in the context of all of the other changes. This integration testing will typically address problems that have been fixed and features that have been added or changed. It may also focus on a quick and basic assessment of the overall product quality.
Regression testing: More often than not, a new set of changes is going to break some existing functionality. Software is notorious for this behavior. Running a full set of regression tests is expensive at times, so it is important to identify the frequency and approach. Perhaps 80% of the tests can be automated and run relatively quickly, thus allowing a partial regression test with every build. Your plan must pay close attention here. You must ensure that you record test results against the build and that you can easily trace through these results and align them with the requirements to give you a clear requirements traceability matrix for both coverage and success/failure.
Your CM Plan must address how test cases are to be categorized, managed, and accessed. Change control may be much different than for source code as test cases typically are more snippet based and hence individual cases change less frequently. Instead, they are typically supplemented with new test cases to address new functionality or non-conformance issues.
Just the Start
There are a lot of areas I've not addressed. There are many things I said that others might be willing to contest. We’re putting a plan together to do the best we can across the application lifecycle management process. Anyone with experience can add valuable input.
So this is a start. Your CM Plan is not going to name tools and processes as requirements. It may use some examples, but technology is constantly changing. Your goals are what is important here. Aim high. If you're aiming lower because technology has to catch up, you've both missed the point of the Plan and have underestimated the available technology and people.
Should there be a common industry CM plan? No. Should there be common components and industry vertical common plans? Probably. Make your plan available at CM Crossroads. Ask others to review it and even pay them to do so. Maybe we'll get there one day.
