In his article "Data Crunching Tips and Techniques," Greg Wilson taught us how to translate legacy data into XML. In the second half, he explains how to merge new data into an existing database. Developers will always face these types of data crunching problems, and knowing the standard data crunching tools can save you a lot of time. Greg also shares the basic knowledge about relational databases that every developer should possess.
An hour and a half ago, the boss announced that we need to write a tool to convert old, flat-text configuration files for the company's major product into the new XML format used in the next release. The tool also needs to be able to merge parameters from a relational database, since some genius (no longer with the company) decided that an earlier version of the product would keep its configuration there.
This job is an example of the kind of data crunching that programmers have to do over and over again. The first article in this series explained the use of regular expressions and DOM to tackle converting data. In this article, I introduce the absolute minimum about relational databases that every developer should know, and discuss how to use it to solve the rest of the data-crunching problem.
Merging with Database Information
It's now 10:30 a.m., and the first half of the job is done; we can convert old-style text files into the new XML format. Time to worry about the second half-merging information from the database. When the boss issued the assignment, we didn't even know there was one, but it turns out that an earlier version of the product allowed users to store shared parameters in a relational database, which was dropped in later releases. If we're going to upgrade, we might as well do everything at once and right the first time.
Crunching databases is a bit different from crunching text files and XML because someone else-in this case, the database manager-owns the data you want. In order to get it out, we have to:
- Connect to the database (which often requires authenticating)
- Construct an SQL query
- Read the query's results
For this job, the values we need are all in a single database table called
Settings, which has three columns (Figure 1):
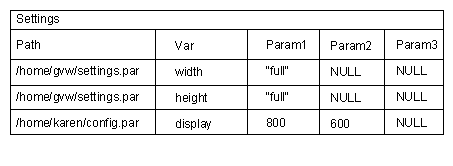
Path, which was the absolute path to the user's parameter fileVar, which was the name of the variableParam1,Param2, andParam3, which held either parameter values (as strings) orNULL.
This is a lousy design for two reasons. First, if a user decides to move her parameter file to a new location or rename it, the database would become confused. Storing the user's ID would have been much better than storing the
path, but still far from perfect. Second, this schema only allows a variable to have three parameter values, but one (the intervals
variable shown in the previous article) has four. Even if that weren't the case, padding tables with enough columns to handle the worst case always leads to code that is complex and fragile.
The right way to handle this would have been to use two tables. The first would record the user identifier (either the path to the configuration file or the user ID), the variable name, and the number of parameters. The second would record the user identifier, the variable, the index of the parameter, and the parameter's value (Figure 2).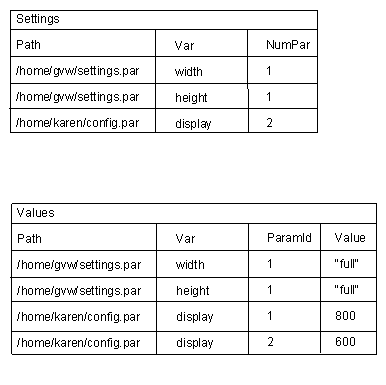
But we have to work with what we're given, so let's modify the crunching script so that the database name is the first parameter, before all the input files. Then we'll add a new function, merge, to combine values from the database into the XML document we've already built:
Now to write the merge routine. This has two parts--one to grab values from the database, and another to put them into the XML document. The database part looks like this:
The first line of this function connects to the database. In Python, as in other languages, database connections are managed by driver classes that, in theory, all offer the same interface. In order to use MySQL or PostgreSQL instead of SQLite, we should only have to change the import statement that loaded the driver and the connect statement that created the link. In practice, each database supports a slightly different dialect of SQL, so it's common to have to tweak our queries as well.
Once we have a connection, we create a cursor. This marks our place in the database, just as an editor cursor marks your place in a document. We can then execute the query, which we pass to the cursor as a string. Following is the fetchall call that grabs the
query's results in one go. If we were expecting a lot of data, we might page through the results instead.
Next, we process the results of the query (discussed below). Once that's done, we close the cursor and then close the connection. Forgetting to tidy up is a common mistake, and while it won't cause an immediate crash, your program may eventually fall over because it has run out of connections.
The processing inside the loop separates the variable's name from its parameters and then tries to find a matching node in the XML document. If the node exists, its parameters' values are overwritten. If it doesn't, a new node is created and appended to the document:

The full text of the functions findVarNode,addOrReplaceParam, andaddVarNode can be found in sample code online.
It's 11:30 a.m., and the script is humming away happily in the background. Of the two-and-a-half hours it took to solve this problem, almost an hour involved tracking down information about file formats, making sure files had the right permissions, and so on; coding and testing only took about ninety minutes. Knowing how to use standard data-crunching tools--the Unix command line, regular expressions, DOM, a little SQL, and most importantly a scripting language (in this case Python)--is the reason it took so little time. We can use data-crunching tools to solve many development project problems, and investing a few hours in mastering them pays enormous dividends.
Click Here to Read Data Crunching Tips and Techniques