Tired of guesstimating your estimation process just to create a completion date management will accept? Jonathan Kohl takes the guess work out of estimations by focusing on uncertainties. It may sound counterintuitive, but the idea is to focus on the fact that all projects face unforeseen delays. The rigorous estimation process Jonathan describes here provides your team a way that ensures enough time is scheduled for development and a date for completion management can agree upon.
Steve McConnell's Software Estimation: Demystifying the Black Art is a fabulous resource for software projects. If you haven't read it, pick up a copy and work your way through it. It is full of great ideas, interesting concepts, and some tips. The topic of software estimation is large, so in this article I'm going to focus on one of McConnell's topics: using uncertainty factors in estimation work.
McConnell writes, "Accurate software estimates acknowledge that software projects are assailed by uncertainty from all quarters." [1] Most software development professionals I've talked to agree with this statement, and there are plenty of estimation tools available with this concept built in. However, I rarely see uncertainty factors applied to project estimation. Management feels the technical staff is uncooperative and inflates estimates, and techies feel that management doesn't have a true appreciation for how much work is required. Using a bit more rigor in our estimation process can make estimation efforts visible, defensible, and more accurate. (Also see Joel Spolsky's feature article Beat the Odds in the March 2007 edition of Better Software magazine. [2])
Example: Scrum Team
A Scrum team was struggling with their estimation process. They'd tried different techniques, including using story points instead of time blocks, but in the end, a senior manager would get a date in mind and the estimates would have to be massaged to meet that date. The fact that they never met that date was a cause for concern.
To combat the confusion, I proposed a new methodology. I would use an estimate-uncertainty factor and Monte Carlo simulations (statistical methods of generating possible future outcomes, used in scientific studies and other fields [3]) to come up with a target release date range which we would present to management for further discussion. Each item in the estimate date range would have an associated probability of completion attached to it. Early items start out with a zero percent probability, and dates further in the future start to move slowly towards a one hundred percent probability.
The uncertainty factor is a number that is associated to a raw estimate (estimate team members provide for a task) and used in the Monte Carlo simulations to generate possible outcomes. It maps to our confidence in the estimate value the team comes up with. In our case, if we had little confidence in the estimate, it was considered a high risk estimate and had a larger uncertainty factor assigned to it. If we had a lot of confidence in the estimate, it was deemed a low risk estimate, with a smaller uncertainty factor.
Prior to meeting as a group to generate raw estimates, I met with each individual team member to determine if they added time to their own raw estimates. For example, when determining a raw estimate of effort, did they secretly pad that estimate by doubling or tripling the time? People often learn to add uncertainty factors without telling anyone. This can distort estimation efforts, particularly if more than one person on a team does this. I told them in our estimation brainstorms to just provide raw estimates but to communicate them in terms of probability or confidence. Are they highly confident in their estimate (a low risk), somewhat confident (medium risk), or not that confident (high risk)? In statistical terms, we could express them as "most likely" (the mode), "average" (the mean), or a "50/50 chance" (the median). The tool uses our estimate, our assigned uncertainty factor, and a random number generator to simulate probable futures.
Once we met as a group, we started creating a list of tasks related to the project. I encouraged the team to list every task related to the software project that took any time, effort, or money. Setting up new environments, purchasing equipment, doing installations, etc. all take time and need to be taken into account.
I encouraged team members to review our list of tasks and bring any past information about how long similar tasks had taken to complete in the past. In our case, we used days of effort as our measure. When it came to generating raw estimate numbers, the team might be unanimous or vary to a great degree. If there were large variations, I took the average and noted it as a "high risk" or, if the variation was smaller, a "medium-risk" estimate. New tasks that didn't have any historical data behind them they would also be high or medium risks. If it was an estimate based on historical information, then it would be a low-risk estimate. The end result was a list of tasks with raw estimates with an uncertainty factor.
There are several tools that generate estimates using uncertainty factor and Monte Carlo simulations of possible outcomes. I used one called Galton [4] (named for the famous mathematician) developed by my colleague David McFadzean. We set our uncertainty factors as 1.1 (low-risk estimate), 1.5 (medium risk) and 2 (high). The tool uses a statistical algorithm to apply those factors to our estimate numbers. For example, a medium-risk factor of 1.5 means that the simulation calculates a variance so that 80 percent of the randomly generated tasks' durations fall between the estimate divided by 1.5 and multiplied by 1.5. The number of iterations in a Monte Carlo simulation helps to counter the large effect this would have if you just multiplied your raw estimates by these numbers and left it at that.
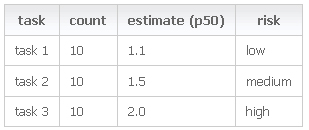 |
Figure 1: Estimates in days with corresponding uncertainty factors
The output of the tool was a graph with an S-curve shape showing a range of dates with associated probabilities assigned:
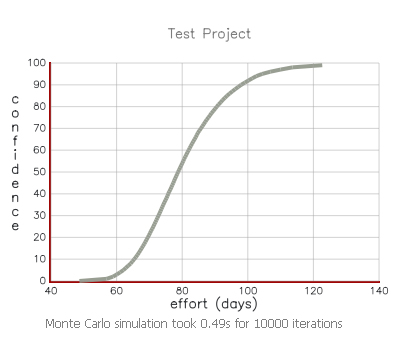 |
Figure 2: Graph with a range of possible outcomes
We used a spreadsheet to add in multiple people in a project over a date range:
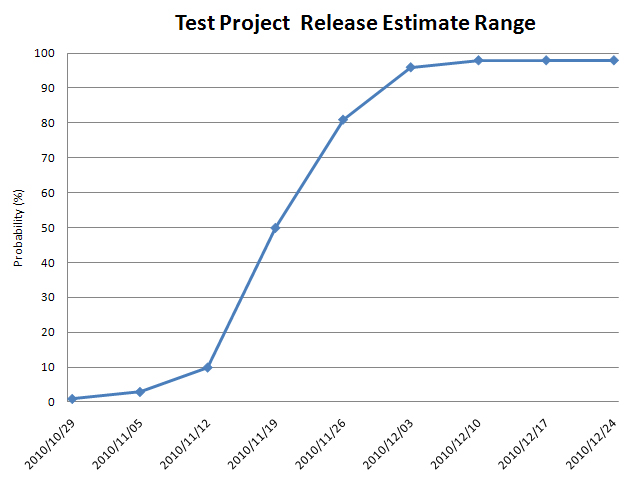 |
Figure 3: Graph with a range of possible outcomes
Instead of communicating one date to management as "the date," we targeted a range of dates with a probability of success around 90 percent. (Refer to Figure 3) The probability for success by looking only at the raw estimates (in Galton, they are called "nominal estimates") was very low. In Figure 2 above, it didn't even show up on the graph. The next step was translating this into effort by adding in how many people we had available on the project. We explained the process, what we used as uncertainty factors, and how many simulations we ran. We wanted to make sure everyone knew how the process worked.
Findings
Management Buy-in
Some interesting outcomes occurred once this was presented to the team. The technical team was worried that management would reject the estimate, but management was much more amenable than they thought. Intuitively, the process and the graph made sense to them. The graph with a date range of possibilities softened the blow of an estimate that was longer than what management had in mind. In fact, management approved almost immediately with little complaint. They were much more comfortable dealing with a probability and a target range of dates than one date with little behind how that date was determined.
Gaming Behavior Needed to be Addressed
Once we started the project, something strange occurred. While the team was pleased that they finally had enough time to complete a project, we caught some of them rushing through tasks to try to complete them more quickly. A bit of investigation revealed that there was far less management pressure on schedules than we had been led to believe. Team members were putting more pressure on themselves, thinking that management always wanted an earlier release. In fact, management was more interested in a quality release. Team members were gaming the system in a way contrary to what management was interested in.
High Degree of Accuracy
At project end, we found that our estimation was very accurate. We did require some fine-tuning, as some of our estimates were wrong. For example, a high-risk estimate may have been scheduled for much more time than our actual effort, but another task that was underestimated filled up that time. We looked at areas of poor estimation and worked on ways to improve them in the future. We also tweaked the values of our uncertainty factors to try to get an even higher degree of accuracy.
Improved Collaboration and Trust
One remark I heard a lot was that estimation finally had some sort of rigor or scientific process to it. Rather than pulling numbers and dates out of some unknown process, we could use a tool to help answer project estimation questions. For example, if a manager asked if we could add more people or cut scope from the project to reach an earlier date, we could easily adjust our inputs and run a new simulation. Sometimes it would help to some extent, and in other cases, we found adding two people and cutting three scope items made a negligible difference on the date range. However, we worked on these efforts together, and we could point to the output of the tool rather than focusing on individuals-"You're pressuring me!" vs. "You're not giving me the right estimate!" Using a tool and process became a shared resource that was less threatening and less stressful than the prior process.
Estimates went from inaccurate, fear-inciting tasks to a process the team looked forward to. All tasks were accounted for and managed in the process, and the team felt they finally had enough time to do what was required. Management felt that they had more visibility on what actually needed to be completed and a more accurate system for providing them with release targets. As time went on, trust was developed between various stakeholders, and estimates became increasingly accurate.
If you are struggling with estimates and haven't thought of using uncertainty factors, I'd encourage you to learn more about this process.
References
[1] McConnell, Steve. Software Estimation: Demystifying the Black Art, Microsoft Press, 2006.
[2] Spolsky, Joel. Beat the Odds, Better Software magazine, March 2007.
[3] Computational Science Education Project Introduction to Monte Carlo Methods.
[4] Galton Estimation Tool (alpha version), Available at: http://estimate.bz
Also see: Wolfram Mathworld Monte Carlo Method.

User Comments
Great article, Jonathan.
I think this area is continually overlooked by agile purists who maintain that "knowledge work [i.e., SW development] cannot be estimated". Of course it can indeed be estimated, just as laying bricks for a wall can be estimated. It is purely a matter of to what degree of accuracy - and precision - it can be estimated [i.e., typically much less well than laying the bricks :-].